To kick off this Everyday Inquiry with R series, I’d like to recount a conversation between my friend Eric and me about one of Americans’ favorite foods, yogurt.
R is a free programming language for statistical computing and graphics, which we’re using in our new National Science Foundation-funded CodeR4MATH project to research the development of students’ computational thinking and mathematical modeling competencies.
The other day I showed Eric my yogurt collection. He was amazed that I had tried so many different brands and flavors.

Eric: Which one is your favorite?
Jie: Currently yogurt-X (a pseudonym of my favorite brand).
Eric: How much is it?
Jie: $1.59
Eric: That’s expensive.
Jie: No, it’s not.
Eric: It is. Take a look at the prices of all the products you collected.
I had previously stored the prices in a vector called ‘yogurt_price’. Below is the simple R code to do that.
# create a vector 'yogurt_price' consisting of yogurt prices yogurt_price = c(1.13, 2.00, 1.69, 1.79, 2.09, 1.00, 1.00, 0.60, 1.00, 1.11, 1.79, 3.19, 1.79, 1.99, 3.69, 2.79, 0.60, 1.79, 1.99, 4.09, 4.49, 4.49, 0.89, 0.89, 1.99, 2.09, 2.09, 2.09, 2.09, 0.69, 1.59, 0.69, 0.69, 0.69, 1.00, 1.19, 7.69)
Jie: Here they are (typing yogurt_price in R console to view the data).
# view a vector yogurt_price ## [1] 1.13 2.00 1.69 1.79 2.09 1.00 1.00 0.60 1.00 1.11 1.79 3.19 1.79 1.99 ## [15] 3.69 2.79 0.60 1.79 1.99 4.09 4.49 4.49 0.89 0.89 1.99 2.09 2.09 2.09 ## [29] 2.09 0.69 1.59 0.69 0.69 0.69 1.00 1.19 7.69
Eric: Nice. How many products did you collect?
Jie: There are…(calling the length() function)
# count the number of elements in a vector length(yogurt_price) ## [1] 37
Jie: 37.
Eric: Oh, that’s a lot. Hmmm, which one is the most expensive (trying to eyeball the greatest number)?
Jie: Well, let me show you…(calling the sort() function)
# sort the elements in a vector sort(yogurt_price) ## [1] 0.60 0.60 0.69 0.69 0.69 0.69 0.89 0.89 1.00 1.00 1.00 1.00 1.11 1.13 ## [15] 1.19 1.59 1.69 1.79 1.79 1.79 1.79 1.99 1.99 1.99 2.00 2.09 2.09 2.09 ## [29] 2.09 2.09 2.79 3.19 3.69 4.09 4.49 4.49 7.69
Eric: Wow, $7.69? And the least expensive is only $0.60. What’s the normal price then?
Jie: Normal? Well, there are a number of $0.69s, $1.00s, $1.79s, and $2.09s. Let me show a frequency count (calling the table() function).
# generate a table of counts for each element in a vector table(yogurt_price) ## yogurt_price ## 0.6 0.69 0.89 1 1.11 1.13 1.19 1.59 1.69 1.79 1.99 2 2.09 2.79 3.19 ## 2 4 2 4 1 1 1 1 1 4 3 1 5 1 1 ## 3.69 4.09 4.49 7.69 ## 1 1 2 1
Jie: There are 5 yogurts priced at $2.09. Is that normal?
Eric: Hmmm…there are four $0.69, four $1.00, and four $1.79. $2.09 seems to be on the expensive end.
Jie: Let’s plot the data points on a number line and see where most prices fall (calling the stripchart() function).
# draw a strip chart for a vector stripchart(yogurt_price)
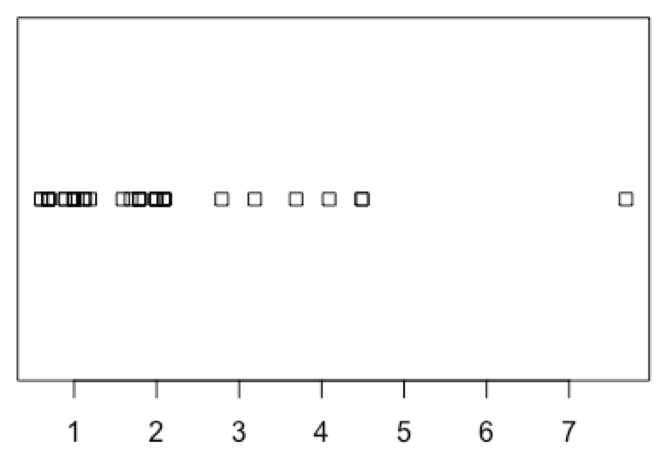
Eric: What is this?
Jie: The x axis is price. Each little square stands for a data point. Some of them are overlapping because the default method is ‘overplot’. Let me make a few changes. We’ll use the ‘stack’ method to stack up data points of the same value. Also, let’s use solid dots instead of hollow squares and set some distance between the points.
stripchart( yogurt_price, method = "stack", # stack up data points of the same value pch = 16, # use solid round label for the points offset = 0.5, # set the distance between points at 0.5 at = 0 # set the location of points to be near the x axis )
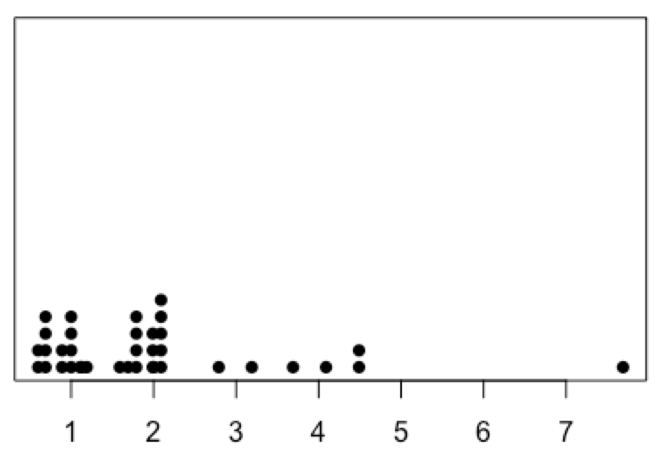
Eric: Beautiful! Looks like there are one, two, three…(counting dots between 0 and 1) 12 products priced at $1.00 or below. And there are…
Jie: You want to see how many products fall in each dollar bracket? Let’s pull out the histogram (calling the hist() function).
# draw a histogram for a vector hist(yogurt_price)
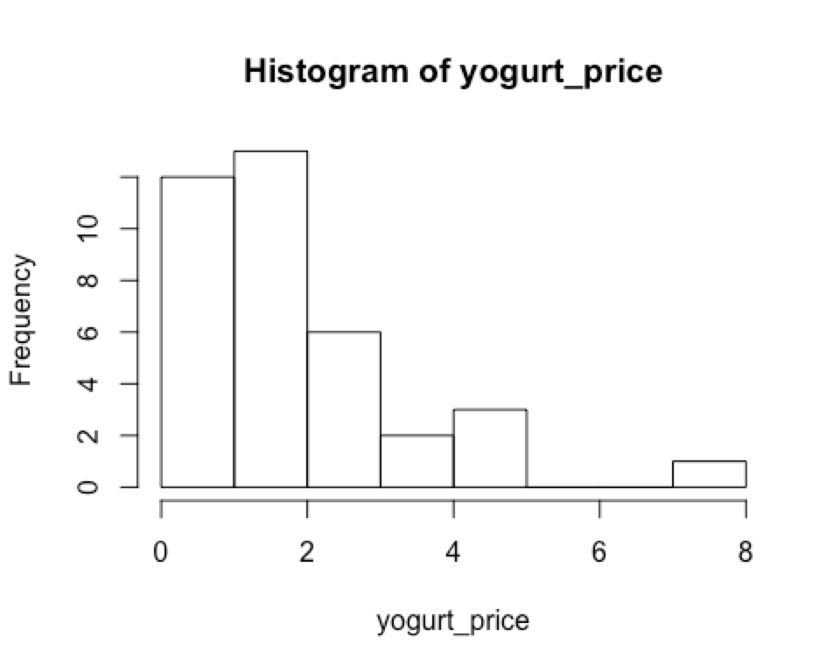
Eric: That saves me a lot of time counting. There are 12 products between $1.00 and $2.00. Your yogurt-X is $1.59. I am sure there are a lot below $1.50. Can you narrow the bins so I can see how many cost less than $1.50?
Jie: Sure! (specifying the breaks argument for the hist() function)
hist( yogurt_price, breaks = 16 # set the number of breaks or bins at 16 )
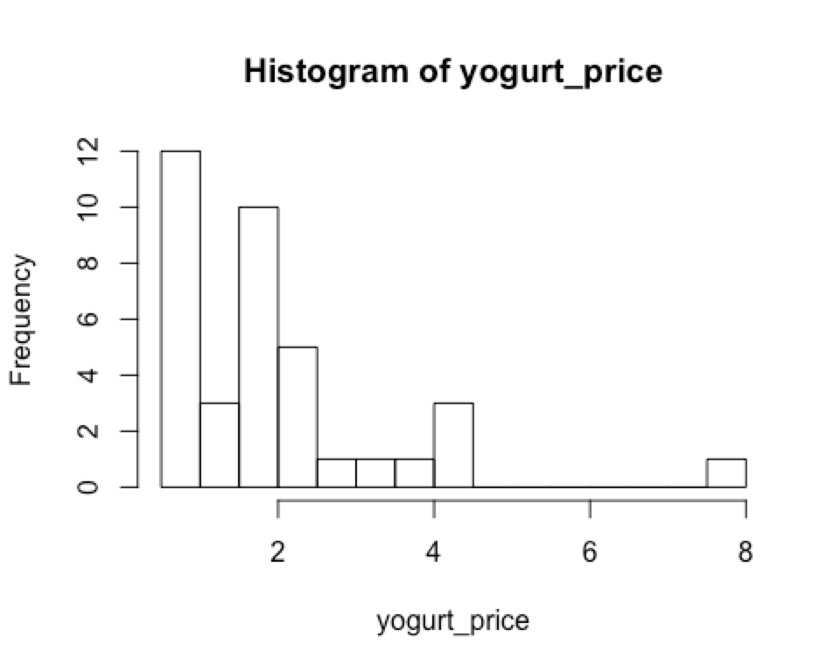
Eric: See? There are 12 (between $0.50 and $1.00) and 3 (between $1.00 and $1.50), a total of 15 under $1.50. Your yogurt-X is the 16th and there are 37 yogurts in total…
Jie: So yogurt-X is on the cheap side.
Eric: Wait a second, these are over $3.00 (pointing to the middle part of the histogram)? I have never seen yogurt that expensive. What are they?
Jie: Oh, oops… (checking yogurt collection table), they are family-sized products. My bad.
Eric: Yeah, that’s not even a fair comparison.
Jie: Right, we need to look at products of the same size.
Eric: Also, perhaps the same yogurt type, flavor, organic or not, etc.
Jie: Exactly.
Obviously, our inquiry did not start out to be very scientific. But that’s okay. It is the process of seeking knowledge. We explore just because we are curious. We argue just because it is stimulating and fun.
And there is nothing exclusive about R. You don’t need a degree or a job to use it. As long as you have some questions and data that may answer those questions, R is amazingly empowering.
I plan to write on this Everyday Inquiry with R theme for K-12 teachers and students. If you have suggestions, please leave a comment. In the meantime, I encourage you to try R and discover its power on your own.
Note: I’m excited that this blog post will also be published on R-Bloggers.com, which aggregates content contributed by bloggers who write about R. Learn more about all things R.
This material is based on work supported by the National Science Foundation under Grant No. 1742083. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
One thought on “Everyday Inquiry with R: Is Yogurt-X Expensive?”
Comments are closed.
fun. What about providing an R notebook and giving the reader an exercise they could do ….