Category: Tag: computational-thinking
From local environmental justice issues to global phenomena such as climate change, complex problems often require systems thinking to address them. Since 2018, the National Science Foundation-funded Multilevel Computational Modeling project, a collaboration between the Concord Consortium and the CREATE for STEM Institute at Michigan State University, has researched how the use of our SageModeler […]
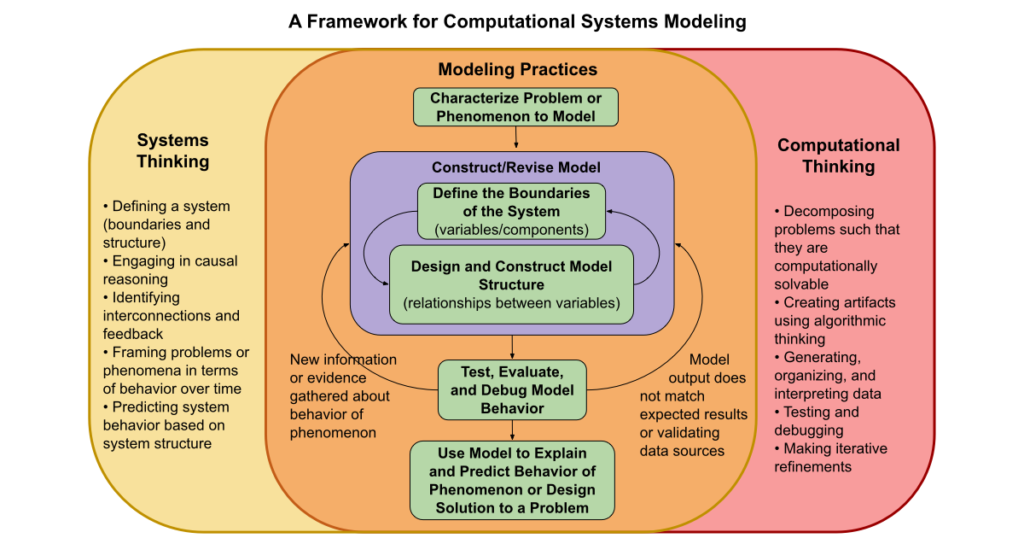
Our Multilevel Computational Modeling collaborative project with Michigan State University has developed a novel theoretical framework based on a literature review of modeling, systems thinking (ST) and computational thinking (CT). The framework, which was also informed by years of work developing our SageModeler systems modeling software and researching student modeling, highlights how both ST and […]
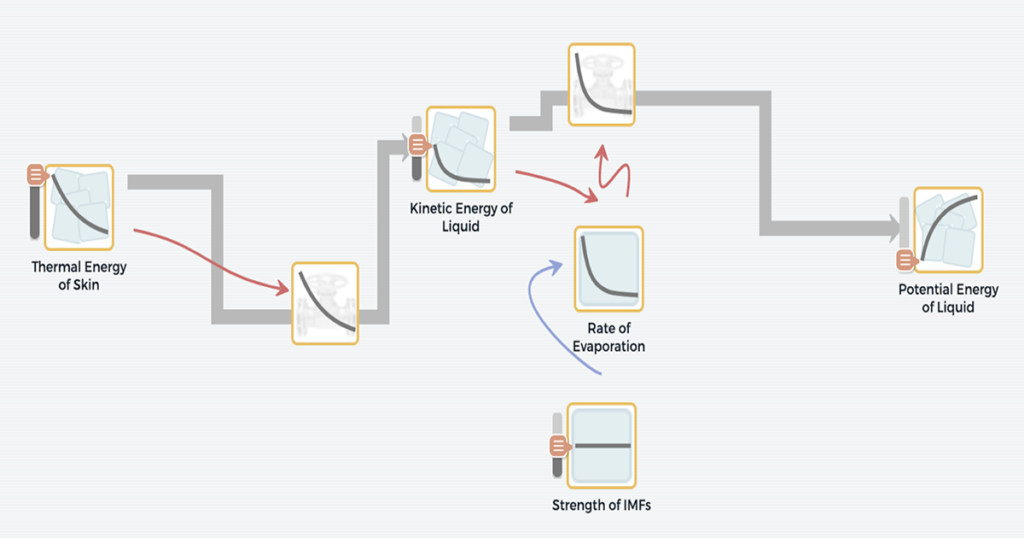
Have you ever wondered why, even on a very hot day, you feel cold when coming out of a pool, lake, or sprinkler? The Multilevel Computational Modeling project, a collaboration with the CREATE for STEM Institute at Michigan State University, has developed a new curriculum unit called “Why do I feel colder when I am […]

Positioning middle school students in a culturally congruent epistemological stance (student-as-anthropologist), allowing them to build Earth science learning from both Indigenous knowledge as well as Western-style inquiry.
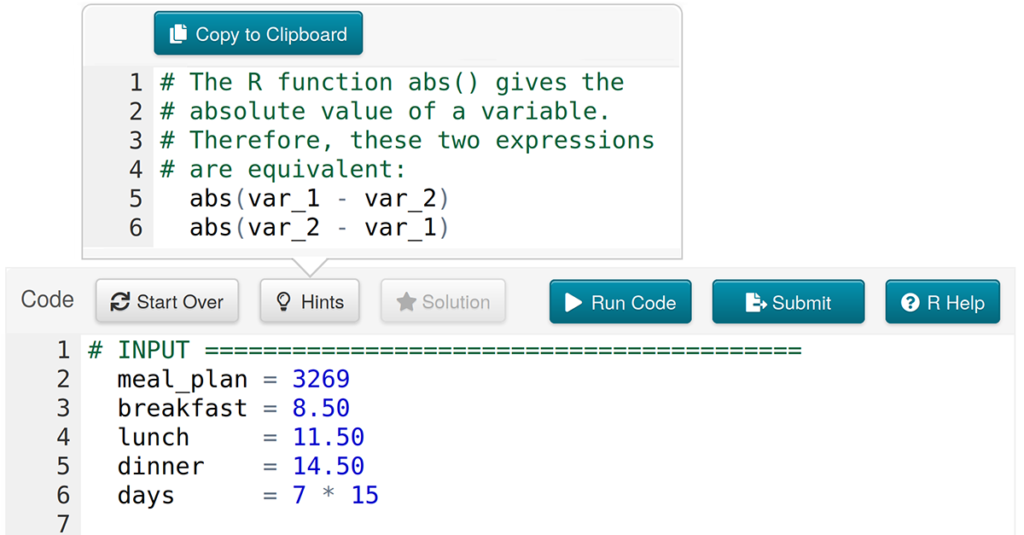
You could say that Concord Consortium’s project Coding with R for Mathematical Modeling (CodeR4MATH) is very sneaky, says Kenia Wiedemann, a postdoctoral researcher on the project. Creative is a different way of describing how CodeR4MATH is getting high school students—especially those who think math and computer science are not for them—coding and creating mathematical models, […]
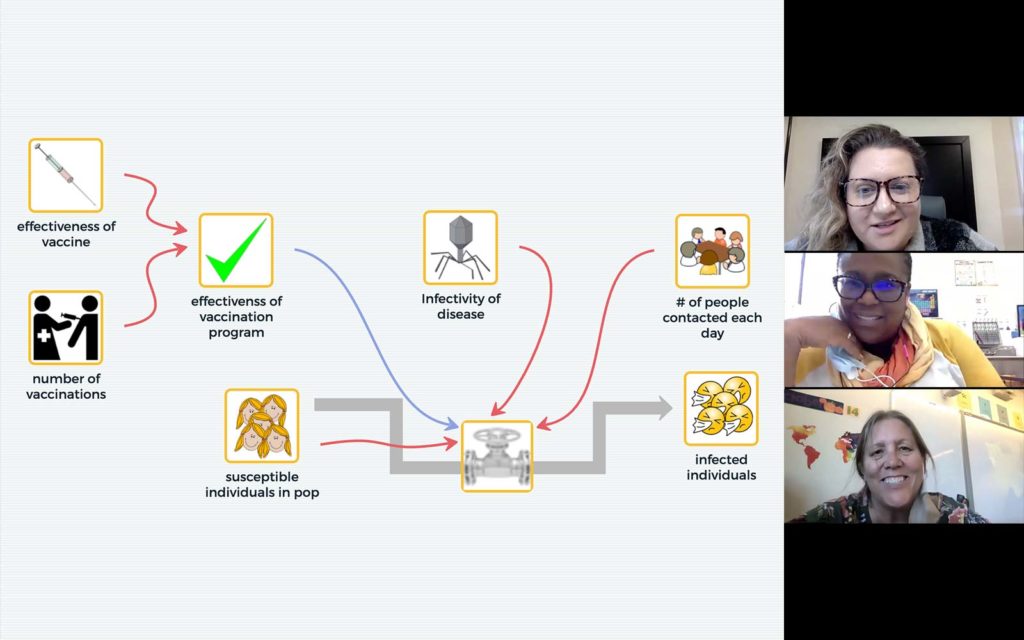
The Concord Consortium and Michigan State University are collaborating to offer remote professional learning to high school teachers to engage their students in three-dimensional learning using SageModeler for system modeling and computational thinking.
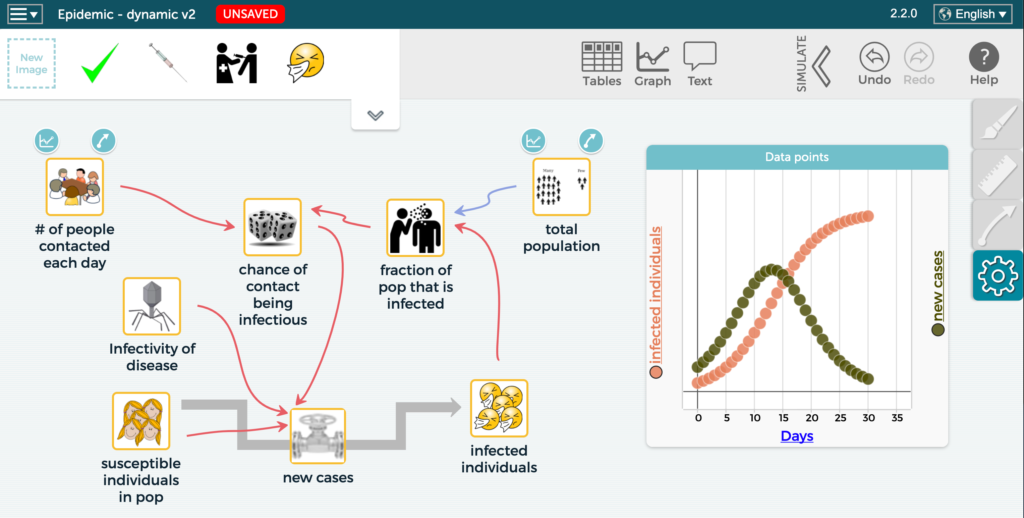
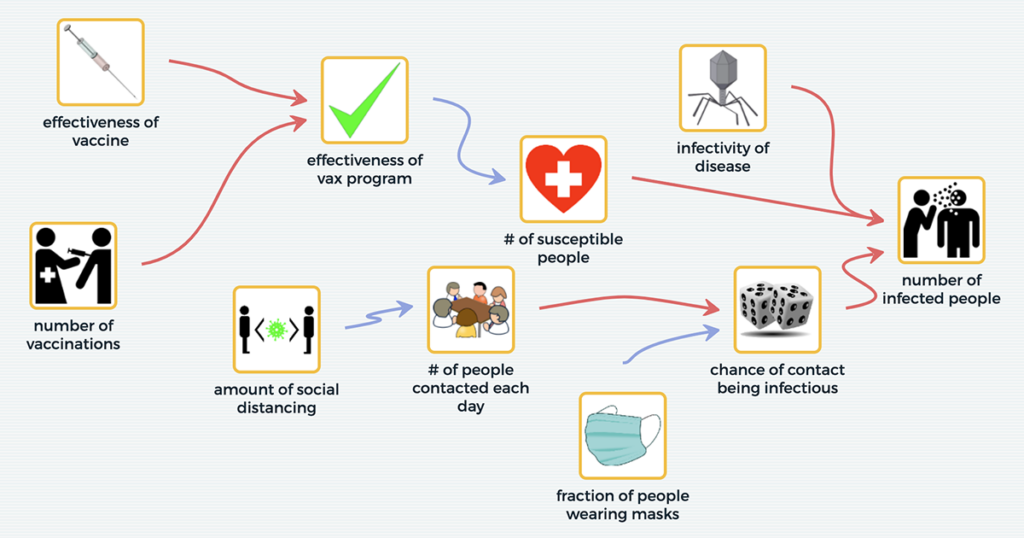
Understanding responses to the current COVID-19 pandemic and solving other pressing global and local problems requires the ability to develop and use models and apply both system thinking and computational thinking. The Next Generation Science Standards (NGSS) include systems and system models as one of the crosscutting concepts, and developing and using models and using […]

Volcanoes are some of the most impressive and unstoppable features on Earth. From the amazing artifacts at Pompeii to the photos of forests flattened by lava flows, the dangers associated with volcanoes are both terrifying and awe-inspiring. However, despite the risks, millions of people live in constant threat of damage to their homes, and more […]

The Concord Consortium and Michigan State University are collaborating to research technological, curricular, and pedagogical scaffolds needed to support students and teachers in developing computational thinking in the context of system modeling.

Six high school mathematics teachers from Massachusetts joined us last fall to pilot test a new curriculum module designed by the Computing with R for Mathematical Modeling (CodeR4MATH) project to facilitate the instruction of mathematical modeling and computational thinking. The CodeR4MATH team (from left to right): Kenia Wiedemann, Jie Chao, Ben Galluzzo, and Eric Simoneau. […]